Information Retrieval is the science of searching for documents, acting as the bridge for knowledge transfer from information producers to information demanders. It goes beyond simple web searches, encompassing image searches, video, audio, library catalogs, and specialized filtering services.
- Database Search: Typically used by programmers who formulate precise queries based on a specific schema, usually interacting through an application. Relies on deterministic models, precise schemas, and exact matches. It is highly sensitive to errors.
- Information Retrieval: Designed for the end-user who has a vague and natural language queries. It operates on probabilistic models to find the “best” or “partial” matches and is generally insensitive to minor errors.
Kuhlen’s model : Data, Knowledge, and Information represent a progression from raw encoding to actionable solutions.
Data (The Syntactical Level):
- Data relates to the purely structural or syntactical level. Anything that is just raw structure with no meaning attached is data.
- It involves defined procedures of data processing.
- Examples include basic file formats and character encodings like Unicode, ASCII, XML, and PDF
Knowledge (The Semantical Level):
- Knowledge moves one step higher to the semantical level, which deals with meaning.
- This represents the actual document content.
- It relies on justified procedures of knowledge representation.
Information (The Pragmatical Level)
-
Information is tied to the pragmatical level, which focuses on practical application.
-
It involves controlled information processing aimed at informational action assurance.
-
Utilizing the system for finding the solution to a user’s specific need.
-
Moving from the syntactical (Data) to the semantical (Knowledge) level requires Representation
-
Connecting the semantical (Knowledge) level with the pragmatical (Information) level requires Extraction.
Typical Tasks in Information Retrieval (IR)
- Query Processing : Taking a user’s formulated information need (the query) and searching the system to find and rank relevant documents. The system processes the query against its index to return a ranked list of relevant web pages or internal documents
- Classification : Organizing and categorizing documents into predefined structures or hierarchies
- Example: Automatically or manually sorting new patents into specific technical categories in a patent database
- Example: An email system automatically sorting incoming mail into Spam, Promotions, or Primary.
- Browsing : Allowing users to manually navigate through a structured collection of documents or categories without having to issue a specific keyword search
- Information Filtering : Actively monitoring a dynamic, ongoing stream of incoming documents and selecting those that match a user’s predefined interests or profile.
- Example : Google Alerts, which constantly scans the newly published web content and sends you a notification whenever a new article mentions a specific topic you are tracking.
Main Aspects of a Retrieval Model When designing or analyzing an Information Retrieval (IR) model, there are four fundamental aspects to consider:
- Representation of the Information Need: How the user’s query is translated into a format the system can understand (e.g., a Boolean logic statement or a mathematical vector).
- Representation of the Documents: How the raw documents are stored and indexed by the system so they can be easily searched (e.g., using extracted keywords or feature vectors).
- Matching: The specific mathematical or logical method used to compare the query representation against the document representations to find relevant results.
- Implementation: The underlying technical execution, data structures (like inverted lists), and algorithms used to make the search efficient and scalable
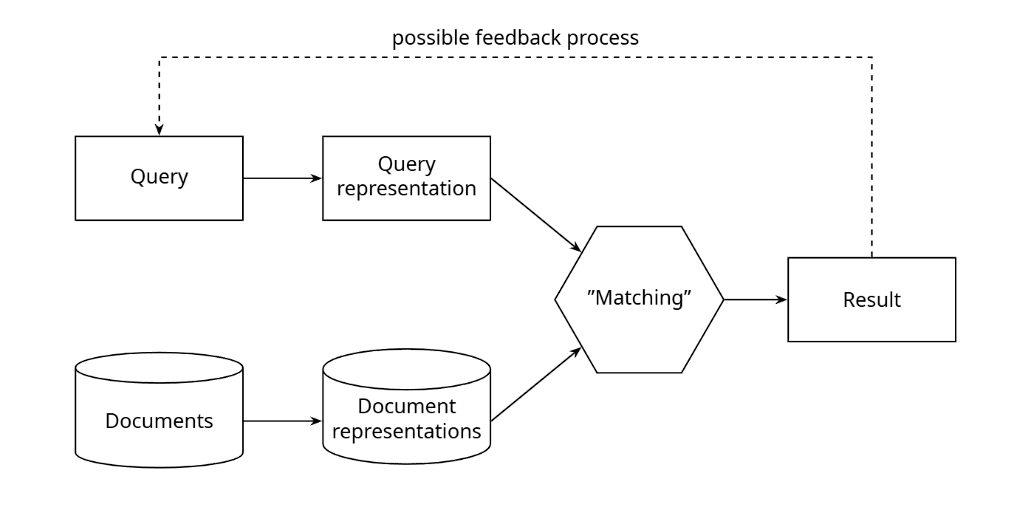 There is also a possible feedback process where the user evaluates the results and refines their query, starting the loop over again
There is also a possible feedback process where the user evaluates the results and refines their query, starting the loop over again
Models of Information Retrieval
-
The Boolean Retrieval Model
Based strictly on classical set theory and Boolean logic (AND, OR, NOT).
- A query is formulated as a logical statement (e.g., “economy AND industrialization”). The system searches the index and retrieves the unstructured set of documents that strictly satisfy this logic.
- Matching: It relies on an exact match. A document either perfectly matches the query conditions, or it doesn’t. There is no middle ground.
- Does not rank documents. A document that contains the word “economy” 50 times is treated exactly the same as a document that contains it only once, because there is no term weighting.
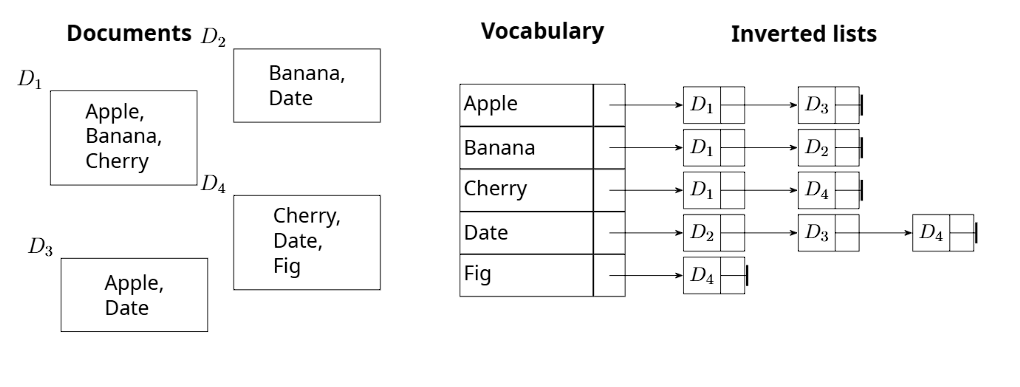
- It is highly efficient for the computer to process using inverted lists. However, it is difficult for users to formulate good queries , the size of the results is highly unpredictable , and the lack of ranking makes it poor for modern web searches.
Inverted lists The system creates a vocabulary of all terms. For each individual word, it manages and saves a list of all the documents that contain that specific word
-
The Vector Space Model (VSM)
This model solves the rigid limitations of the Boolean model by treating language geometrically.
- Both the user’s query and the documents in the database are transformed into multi-dimensional vectors within a shared mathematical space.
- Before the system can convert text into a vector, the raw text must be cleaned and standardized. This involves several critical steps:
- Stop Word Elimination: Removing common words that carry little to no independent meaning (e.g., “and”, “or”, “the”).
- Stemming: Tracing all occurring word variants back to their base or root form (e.g., reducing “emperors” to “emperor”).
- Synonym Handling: Replacing synonyms with a single, preferred uniform term to ensure consistency
- Each distinct term in the vocabulary represents a different dimension (or axis) in this space.
-
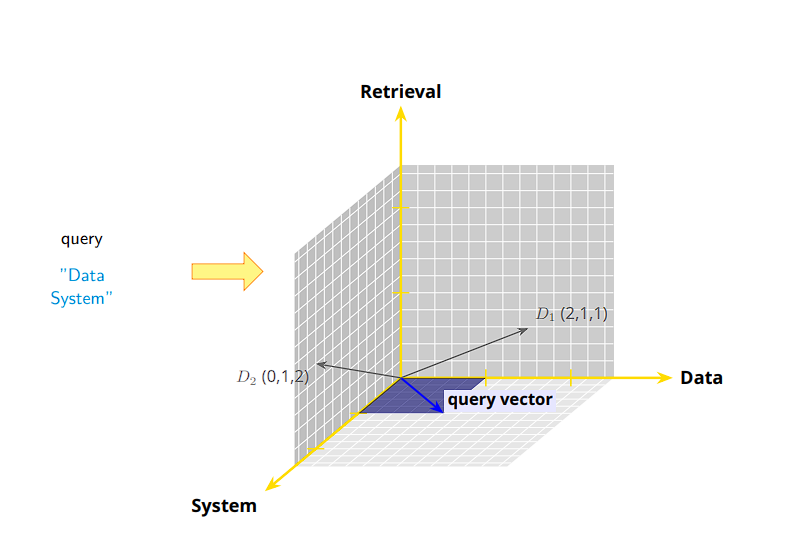
Example : Consider an entire vocabulary of only three words. Because there are three words. Vocabulary (The Dimensions): Dimension 1 (x-axis): The word ”Data” Dimension 2 (y-axis): The word ”Retrieval” Dimension 3 (z-axis): The word ”System”
Document 1 (D1): ”Data Data Retrieval System” → D1 = (2, 1, 1) Document 2 (D2): ”Retrieval System System” → D2 = (0, 1, 2) Query (Q): ”Data System” → Q = (1, 0, 1)
-
- It allows for partial matches. Instead of a binary yes/no, it calculates the weight of each term using the TF-IDF formula (Term Frequency-Inverse Document Frequency). This ensures that words appearing frequently in a document () but rarely across the whole collection () are given the highest importance.
- Term Frequency-Inverse Document Frequency (TF-IDF)
- Term Frequency (): This factor accounts for how often a specific term appears within a single document. A higher frequency means the term is highly relevant to that specific text.
- Inverse Document Frequency (): This factor accounts for the term’s “discriminative power”. It measures how rare or common the term is across the entire collection of documents. The TF-IDF Formula (Vector Space Model) To determine the specific weight () of a term () within a specific document (), the model uses the following formula:
= Number of terms in the entire vocabulary. = Total number of documents in the collection. = Number of documents containing the specific term . = Frequency of occurrence of term within document .
**The Numerator ($tf_{dk} \cdot \log(N/n_k)$):** This calculates the core weight by multiplying the term's frequency in the document by its discriminative power (the inverse document frequency).
**The Denominator:** This acts as a normalization factor. It divides the score by the overall length of the document's vector to ensure that naturally long documents don't get an unfair advantage over shorter ones.
- Once the query and the documents are vectorized using TF-IDF, the system must determine which documents are the most relevant. This is calculated using the scalar product (The angle, $\alpha$, between the query vector and the document vector). A smaller angle means a higher similarity.
- It provides a ranked result list and handles vague queries well.
- It assumes all words are independent of each other (ignoring the order of words and context).
-
The Probabilistic Retrieval Model
Attempts to calculate the actual mathematical odds of relevance.- Uses Probability Ranking Principle (PRP). The core idea is to estimate the probability that a specific document will be relevant to a specific user’s query, separating documents into a “relevant” set and a “non-relevant” set.
- It uses statistical probability rather than spatial geometry. Modern implementations (like the famous BM25 algorithm) calculate term weights based on the distribution of terms across the relevant and non-relevant documents.
- Documents are ranked in decreasing order of their calculated probability of relevance.
Evaluation of IR Systems When evaluating an IR system, the focus shifts from absolute “correctness” (which is indispensable for traditional database systems) to the “quality” of the results To measure quality, the standard evaluation model relies on a basic assumption: for any given query, it can be uniquely and definitively decided whether each document in the system is relevant or not relevant.
- Recall (Completeness):
- Question: How complete is the result?
- Definition: The portion of relevant documents found out of all the relevant documents that exist in the entire database.
- Example: If there are 100 relevant documents in the system, and your search finds 50 of them, your Recall is
- Precision (Accuracy):
- Question: How accurate is the result? Does it contain only relevant entries?
- Definition: The portion of relevant documents out of the total documents returned in the result set.
- Example: If your search returns 75 documents, but only 50 of them are actually relevant, your Precision is roughly An IR system must also evaluate the “quality” of the result documents. For example, the system needs to distinguish between a highly specific research article and a general overview article, deciding which is better for the user.
For web search engines, measuring intrinsic quality automatically is difficult. The breakthrough idea was to use the structure of the web itself : Many links pointing to a page indicate high quality. If many websites link to a page, they are essentially “voting” for its usefulness. This concept was implemented as the PageRank method by Google
The PageRank Formula The PageRank of page ():
-
: The PageRank of the target page .
-
: A parameter (damping factor), typically set between and .
-
: All the pages () that contain a link pointing to page .
-
: The PageRank of the linking page .
-
: The total number of outbound links exiting page . (A link from a page with 100 links is worth less than a link from a page with only 1 link).
-
Note: Because it’s recursive, the values are calculated in an iterative procedure usually taking 5 to 50 iterations to stabilize.
Problems with PageRank
- No Thematic Weighting: All links are treated equally regarding topic. A link from a cooking blog to a physics paper passes the same PageRank as a link from a prestigious physics journal.
- Age Bias: The number of links heavily depends on the “age” of a page. Older pages have had more time to accumulate links, making it hard for high-quality new pages to rank.
Modern search engines look at numerous other criteria to establish quality, such as:
- Up-to-dateness: How recent is it? (e.g., via modification date) .
- Availability: Is the site online and loading fast?.
- Information Content: Does it have a high density of technical terms/words?.
- Popularity: Is it getting social media “likes” or high traffic?.
- Authority: Has it received positive manual assessments?.
- Cohesion: Is the content dense and focused (proximity of the terms used)?.
The IR system must combine its TF-IDF score (Content Relevance) with its PageRank/Quality score. Mix both content relevance (does it match the query?) and quality (is it a good source?) to provide a balanced result list.
The system can combine these by simple Addition or Multiplication.
- Diversifying the Results (The Malus System): If a system just plots Relevance against Quality, the top results might all be highly similar documents from the same cluster. To ensure a diverse result list, a mixing approach is used: When a top document is included in the final result, “neighbor documents” (documents that are extremely similar to it) receive a malus (a penalty). This ensures that documents with a different character or perspective follow each other in the search results, giving the user a better, varied experience.
Content-Based Image Retrieval (CBIR) applies these concepts to other media.
- Instead of words, the system extracts characteristic visual properties (features) like color, texture, and shape to create a query vector.
- For instance, a Color Histogram sorts pixels into RGB bins. The system can then match the histogram of a query image against the histograms of documents in the database to find visual similarity.
Context-Based Information Retrieval (IR) Traditional IR systems rely solely on the exact keywords a user types into the search bar. Context-Based IR takes this a step further by asking: What else do we know about this user that could help us figure out what they actually mean? The goal is to use external sources and background knowledge about the user’s environment to concretize their vague information need. To make context-based search work, the system builds a comprehensive “User Model.” This model aggregates data across several dimensions:
- Interaction Context: What is the user doing right now? This includes tracking immediate events, actions, and sequences of actions on the computer.
- Work Context: What is the user’s current goal? This involves tracking structured tasks (workflows) and unstructured tasks using past data and current snapshots of activity.
- Physical Context: Where and when is the user searching? (Geographical and Temporal data).
- Organizational Context: What is the user’s job or role within a company?
- Profiles: What do we know about the person? This includes their personal profile (interests, skills, general knowledge) and task-specific profiles. The system architecture for context-based IR functions by continuously running in the background and gradually increasing the “semantic level” of the search:
- Data Collection: Plug-ins inside the user’s daily applications (like Word, a web browser, or an email client) observe system events, user actions, and emerging information needs.
- Transformation Layer: These raw events are passed down into a transformation layer.
- Unified User Model: The data is fed into the unified user model via connectors (linking to organizational directories, personal preferences, and workflow rules).
- Automatic Generation: Finally, instead of waiting for the user to type a perfect query, the system uses all this background context to automatically generate and execute a highly precise query in the Retrieval System, pushing recommended documents and information directly to the user’s portal or results list.
Evaluation and Assessment of IR Systems The primary goals of evaluating an Information Retrieval system are to enable the comparison between several different systems and to guide the design and configuration of new systems. Efficiency: This refers to using resources as sparingly as possible (e.g., runtime and memory efficiency). Effectiveness: This refers to the quality of a result in relation to the effort expended.
Binary Relevance : To measure the effectiveness of a search result, for any given query (), the entire document collection falls strictly into two parts:
- : The set of documents relevant to the query.
- : The set of documents not relevant to the query.
- The Goal: The quality of an IR system is therefore determined by how perfectly its result set matches (with minimal deviation). Problems of the binary definition of relevance : Prior Knowledge: Relevance is highly subjective. Interdependence of Documents: Relevance can change as you read. Document B might only be relevant if you have already read and understood Document A.
To calculate how well an IR system performs, every document in the database during a search is categorized into one of four states:
-
(Hits): Relevant documents that are included in the result.
-
(Noise): Non-relevant documents that are included in the result.
-
(Misses): Relevant documents that are not included in the result.
-
(Rejected): Non-relevant documents that are not included in the result.
$\Large Recall = \frac{a}{a+c}$ $\Large Precision = \frac{a}{a+b}$ $\Large F\text{-}Measure = \frac{Precision \cdot Recall}{(1-\alpha) \cdot Recall + \alpha \cdot Precision}$
To calculate Recall mathematically, you need to know the total number of relevant documents that exist in the entire database. In a massive system (like the web or a huge library catalog), it is practically impossible to know this absolute number.
Methods for Estimating Recall :
-
Representative Sample: You manually assess a completely representative sample of the database. Problem: The proportion of relevant documents is usually so tiny that your sample has to be impractically large to find them, requiring massive human effort.
-
Document Source Method: You pick a random document from the database, formulate a query that should find this document, and see if the system actually retrieves it. Problem: These reverse-engineered queries are often not realistic representations of how actual users search.
-
Query Extension: You dramatically expand the query (e.g., having multiple experts formulate different versions of the question) to pull a massive “superset” of results. Problem: You still only get a subset of the truth, meaning your Recall estimate will generally look artificially higher than it actually is.
-
External Sources: You ask the person who formulated the query, or domain experts, to list all the relevant documents they already know exist, independent of the search engine.
Averaging Over Multiple Queries & MAP
Evaluating an IR system based on a single query is useless; you must average its performance over many different queries. There are two primary mathematical ways to do this: Macro Assessment (User-Oriented Approach)
-
How it works: You calculate the Precision and Recall for each individual query first, and then you take the average of those final scores.
-
Pros/Cons: It treats every query as equally important, regardless of how many results it brings back. However, a problem occurs if a query returns zero results, as it causes a mathematical division by zero error ().
Micro Assessment (System-Oriented Approach)
-
How it works: You pool all the raw numbers (hits, misses, noise) from every query into one giant sum, and treat it as “one big query”.
-
Pros/Cons: Queries that naturally return a larger set of results will heavily dominate the final average, overshadowing smaller, more specific queries.
MAP (Mean Average Precision)
- Because modern search engines use ranked results (where the best stuff is at the top), researchers use MAP.
- MAP defines specific “measuring points” for Recall (e.g., checking the Precision when Recall is exactly at 10%, 20%, 30%, etc.) and takes the mean value across all these points.
- It is a highly system-oriented metric used to plot those Recall/Precision graphs.