Learning from data is used in situations where we don’t have an analytic solution, but we do have data that we can use to construct an empirical solution.
An example is the Netflix Prize recommendation model which is typically described as a latent factor matrix factorization model trained on observed user–item ratings.
- Viewer Vector (): Represents the user’s preferences.
- Example Factors: Likes comedy? Likes action? Prefers blockbusters? Likes Tom Cruise?
- Movie Vector (): Represents the movie’s attributes.
- Example Factors: Comedy content, Action content, Blockbuster status, Is Tom Cruise in it? The power of learning from data is that this entire process can be automated, without any need for analyzing movie content or viewer taste. To do so, the learning algorithm ‘reverse-engineers’ these factors based solely on previous ratings. It starts with random factors, then tunes these factors to make them more and more aligned with how viewers have rated movies before, until they are ultimately able to predict how viewers rate movies in general. In practice, these factors are not human-interpretable features (like “comedy” or “action”), but latent patterns automatically learned from data, and the model often includes additional bias terms to improve prediction accuracy. Latent factors are patterns that are statistically real but often incomprehensible to humans. We might call Factor #1 “Action,” but to the computer, it is just “Factor 1”.
Neural recommender systems extend matrix factorization by learning user and item embeddings and replacing the dot-product similarity with a nonlinear function (e.g., a neural network).
A learning problem can be defined using four main components: input space, target function, dataset, and hypothesis set.
- (Input): The specific data used to make a decision (e.g., an individual customer’s financial information).
- (Input Space): The set of all possible inputs.
- (Output Space): The set of all possible outputs (e.g., {Yes, No} for credit approval).
- (Target Function): The unknown, ideal, perfect formula that maps every input to the correct output. This is what we are trying to learn.
- (Data Set): A collection of historical input-output examples, denoted as .
- (Hypothesis Set): The set of all candidate formulas the algorithm is allowed to consider (e.g., the set of all possible linear equations).
- (Final Hypothesis): The single, specific formula chosen by the learning algorithm from . The Learning Algorithm analyzes the Data Set () to select the best possible formula from the Hypothesis Set (), with the goal that
There is a target to be learned. It is unknown to us. We have a set of examples generated by the target. The learning algorithm uses these examples to look for a hypothesis that approximates the target.
The hypothesis set and learning algorithm are referred to informally as the learning model.
A Simple Learning Model : The Perceptron Model (Linear Hypothesis)
The perceptron models binary decisions by assigning weights to input features, computing a weighted sum plus bias, and classifying the result using a sign function to separate inputs into two classes (binary classification). Mathematical Formulation :
- Input Space (): A -dimensional vector . Each coordinate () represents a specific data field like salary, years in residence, or outstanding debt.
- Output Space (): A binary set .
- = Approve Credit
- = Deny Credit
- The Hypothesis (): The specific formula used to make the decision. It is defined as:
Weights (): These determine the importance and direction of each input.
Bias (): This represents the threshold.
larger bias → stricter approval boundary
smaller bias → more lenient approval boundary
The perceptron is a linear classification model that learns a hyperplane:
which separates the input space into:
- decision region
- decision region
A perceptron can operate in:
- 2D
- 3D
- 100D
- 10,000D For:
- → separating line
- → separating plane
- higher → hyperplane
Example : Image Classification
Input:
a grayscale image
Flattened into features,
Output:
"cat" vs "not cat"
Perceptron = hypothesis set
Each = one specific linear classifier
Learning algorithm = picks the best
To simplify the perceptron notation, the bias term is merged into the weight vector. The perceptron hypothesis is: Define: and extend the weight vector: Similarly, extend the input vector by adding a constant feature: with . This allows the bias term to be absorbed into the dot product: So the bias becomes just another weighted feature.
Now:
The perceptron can now be written compactly as:
By augmenting the input vector with a constant feature , the bias term becomes part of the weight vector, allowing the perceptron to be written as a single dot product.
The bias term in the perceptron can be absorbed into the weight vector by introducing an additional constant input feature, giving the compact form:
Perceptron Learning Algorithm (PLA) :
An iterative method used to learn the weight vector from data.
Assumption: Linearly Separable Data
We assume the dataset is linearly separable, meaning:
There exists a weight vector such that all training examples are classified correctly.
Start with an initial weight vector:
(or any arbitrary initialization)
At each iteration :
- Current weight vector:
- Select a misclassified example
A misclassified point satisfies:
The perceptron updates weights using:
Intuition Behind the Update
-
moves in the direction of the correct classification
-
increases alignment with correctly labeled examples
-
decreases error on the chosen misclassified point
-
If → move toward
-
If → move away from
At each step: -
only one example is corrected
-
other examples may temporarily become misclassified again
-
rotates the hyperplane slightly in a direction that fixes the current mistake without needing global optimization However:
The process continues until no misclassified examples remain
Perceptron learning primarily rotates the decision boundary by updating the weight vector , while the bias controls translation of the hyperplane.
The hyperplane is defined by: So:
- changing w → rotates the hyperplane
- changing b → shifts it
In the classic perceptron update, the dominant effect is rotation.
The multiplication by is used to unify the two misclassification cases into a single condition with the same mathematical form.
We want to check whether a point is misclassified.
The perceptron predicts using:
So:
- If → positive half-space
- If → negative half-space
Misclassification happens in two cases:
Case A: true label is +1, but prediction is negative
Case B: true label is -1, but prediction is positive
We must check two separate conditions:
- This is cumbersome for analysis and algorithm design.
We define a unified expression:
Case A: Misclassification condition: So :
Case B: Misclassification condition: So again:
Both cases collapse into a single condition:
Multiplying by :
- flips all negatively labeled points
- all +1 points remain in place
- all −1 points are mirrored across the origin
After transformation: Every correctly classified point must lie on the same side of the hyperplane
- correct classification means:
So all points are evaluated against the same rule: “positive alignment” (everything should land in the positive half-space)
This is useful for learning as this allows a single update rule instead of case-based logic: Effect:
- if → move toward
- if → move away from
The weight vector is not the hyperplane itself.
Instead:
is the normal vector to the hyperplane.
That means:
- is perpendicular (orthogonal) to the decision boundary
- determines which side is classified as positive
- the hyperplane is defined relative to
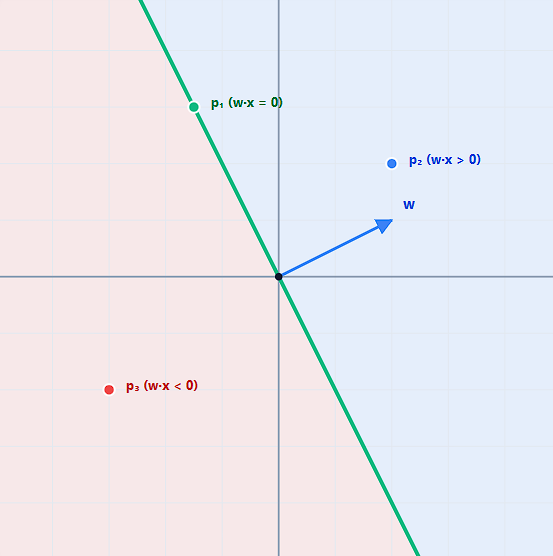
For any two points lying on the hyperplane:
Subtracting:
Thus:
is perpendicular to every direction lying within the hyperplane. The weight vector defines the orientation and positive direction of the classifier, while the hyperplane itself is the set of points orthogonal to that vector.
The Weight Vector Lies in the Positive Half-Space The hyperplane splits space into two regions: Positive half-space: Negative half-space: The hyperplane equation at
$w^T w = \|w\|^2$
$w^T w > 0$
So the weight vector (w) lies inside the positive half-space defined by the hyperplane. The vector :
- points toward the positive region
- acts as the normal vector to the hyperplane
- defines the direction of increasing score The sign of measures alignment with the weight vector:
- positive dot product → same general direction as
- negative dot product → opposite direction
Each perceptron update increases the signed margin of the misclassified point by a strictly positive amount, guaranteeing steady progress toward correct classification (correct side of the decision boundary)
To classify a point correctly, the prediction must agree with the true label. This is captured by requiring:
A point is misclassified when:
Proof:
$$$y(t)w^T(t+1)x(t) = y(t) \left[ w(t) + y(t)x(t) \right]^T x(t)y(t) \left[ w^T(t) + y(t)x^T(t) \right] x(t)y(t)w^T(t)x(t) + y(t)y(t)x^T(t)x(t)$$
- Since is either or , its square is always exactly 1.
- The term is the dot product of a vector with itself, which is equal to its squared length, . Assuming the data point is not the origin (a zero vector), this value is strictly positive ().
The score strictly increases after each update.
Geometric View of the Perceptron Problem
Each training example imposes a geometric constraint on the weight vector .
For a labeled example , correct classification requires:
This can be rewritten as a linear constraint on (Fix , treat w as variable):
The inequality:
defines a half-space in weight space (a half-space of all valid classifiers)** .
We denote it as:
So each training example restricts to lie in a convex region.
For a dataset of examples, we require:
This is:
-
The set of all perfect classifiers
-
must satisfy all constraints simultaneously
-
it must lie in the intersection of all half-spaces
-
Each is convex (a half-space is always convex)
-
The intersection of convex sets is also convex
The feasible set of solutions is a convex region in weight space
Training becomes:
find a point inside the intersection of all half-spaces
The perceptron update:
- starts with some
- moves it whenever a constraint is violated
- if w violates one constraint
- push w toward satisfying that constraint
The perceptron learning problem is equivalent to finding a point in the intersection of convex half-spaces defined by the training data.
Each training example defines a convex half-space constraint on , and learning reduces to finding a point in the intersection of all such half-spaces.
Perceptron learning is iterative navigation through intersections of convex half-spaces in parameter space, not data space.
Why the Perceptron Update Direction is ?
Consider the linear objective:
where:
- is fixed
- is the variable being optimized
We want to determine:
In which direction should we move to increase as quickly as possible?
The answer is given by the gradient.
Taking the gradient with respect to :
So:
the direction of steepest increase is exactly the vector
If the update is constrained to unit length:
then the optimal direction becomes:
which is the normalized version of .
The objective change after a small step is:
So maximizing improvement means maximizing:
Cauchy–Schwarz Inequality
We use:
If , then:
The maximum possible increase is therefore:
Equality in Cauchy–Schwarz occurs only when the vectors are collinear:
Under the unit norm constraint:
The perceptron update:
uses:
- as the optimal correction direction
- to determine whether to move toward or away from the point
Thus:
- positive examples pull toward themselves
- negative examples push away
The perceptron update follows the direction that maximally increases the classification score for the current example.
Lagrange Multipliers: Optimal Update Direction
We want to maximize the directional improvement of the objective:
- Objective: maximize
- Constraint: unit-length update
The Lagrangian says:
“Maximize the objective, BUT punish solutions that break the constraint.”
Differentiate with respect to :
Apply unit norm constraint:
Substitute :
So:
Substitute back into :
If the data is linearly separable:
- PLA is guaranteed to converge
- It will find a valid in a finite number of steps This result is known as the Perceptron Convergence Theorem.
Perceptron Convergence Theorem :
We are given a dataset where:
We assume linear separability, meaning:
There exists a vector such that:
Define:
- (after normalizing so )
So:
- = maximum data norm (The largest length (magnitude) among all training points)
- = geometric margin (minimum confidence)
At each mistake on :
Initialize:
We prove two inequalities: (A) Progress toward optimal direction (B) Growth of norm is controlled Combining them gives the mistake bound.
Step 1 - Consider dot product with (alignment with true solution):
So each mistake increases projection by:
By separability:
So:
So every mistake pushes **closer in direction to .
After mistakes:
Step 2 - Bound growth of
Compute norm growth:
=
Updates happen only on mistakes, for a mistake:
So:
Using :
After mistakes:
From Cauchy–Schwarz:
Assume :
Using bounds:
So:
The number of perceptron mistakes is bounded by:
Each update:
- increases alignment with by at least
- increases weight norm only by at most
So:
alignment grows faster than destructive “noise” in magnitude
This forces convergence.
- Larger margin → faster convergence
- Larger data norm → slower convergence
- Well-separated data → very few updates
If the data is linearly separable with margin , the perceptron makes at most mistakes before converging.
Even though the hypothesis space is infinite, PLA finds a correct solution using only simple local updates based on misclassified points. So convergence is guaranteed in finite steps.
The perceptron converges because its updates increase alignment with the true separator linearly while controlling norm growth sublinearly, forcing a finite bound on mistakes.
Learning from Data vs Design from Specifications
A classic example illustrating the difference between learning from data and design from specifications is coin recognition in vending machines.
The goal is to classify:
- pennies
- nickels
- dimes
- quarters
using:
- coin size
- coin mass
So each coin is represented as a 2D input vector:
In the learning approach:
- we collect example coins from each denomination
- each example becomes a labeled training point
- input → size and mass
- output → coin denomination
Coins of the same type form clusters in feature space.
The learning algorithm:
- observes the training data
- searches for a hypothesis
- learns decision boundaries separating the coin classes
A new coin is classified by:
- measuring size and mass
- feeding the measurement into the learned classifier
In feature space:
- each denomination forms a cluster
- the classifier partitions the space into regions
The boundaries are inferred directly from data.
In the design approach:
- we use prior knowledge instead of training data
- obtain official specifications from the U.S. Mint
- model:
- expected coin size
- expected mass
- measurement noise
- wear-and-tear variations
- relative frequency of each coin
Using this information, we construct a joint probability distribution over:
- size
- mass
- denomination
Once the probability model is known, we analytically derive the optimal classifier.
For a given measurement :
choose the denomination with the highest probability:
This minimizes classification error probability.
In the design approach:
- the problem is fully specified
- we derive the solution mathematically
- Example : Classifying numbers into primes and non-primes, Determining the time it would take a falling object to hit the ground
In the learning approach:
- the target function is unknown
- data is needed to approximate it empirically
- Example : Detecting potential fraud in credit card charges, Determining the age at which a particular medical test should be performed
Types of Learning
Learning from data aims to infer an underlying process from observations. Because real-world settings vary widely, different learning paradigms have been developed.
Supervised Learning In supervised learning, each training example includes both:
- input
- correct output
So the dataset has the form:
The learning algorithm uses these labeled examples to approximate the unknown function:
Example: Handwritten Digit Recognition
Each training sample consists of:
- input: image of a digit
- output: label in
So the dataset is:
The model learns to map images → digit labels.
Active Learning In active learning:
- the algorithm selects inputs
- a supervisor provides the corresponding output So instead of passively receiving data, the model chooses what to learn from.
The learner can ask strategic questions:
“Which example would be most informative?”
This is similar to a game of 20 questions.
- reduces number of labeled examples needed
- focuses learning on informative regions of the input space
Online Learning
In online learning:
- data arrives sequentially
- the algorithm updates after each example
Instead of seeing a full dataset, the learner processes a stream:
The model must:
- learn continuously
- update in real time
Use Cases
- streaming recommendation systems
- real-time user feedback (e.g., clicks, ratings)
- systems with memory or compute constraints
- no full dataset is required